Oral Session: Wed 24 Jul 10:30 AM in [Hall C 1-3]
Position Paper at ICML 2024 (Oral)
Many roboticists dream of presenting a robot with a task in the evening and returning the next morning to find the robot capable of solving the task. What is preventing us from achieving this? Sim-to-real reinforcement learning (RL) has achieved impressive performance on challenging robotics tasks, but requires substantial human effort to set up the task in a way that is amenable to RL. It's our position that algorithmic improvements in policy optimization and other ideas should be guided towards resolving the primary bottleneck of shaping the training environment, i.e., designing observations, actions, rewards and simulation dynamics. Most practitioners don't tune the RL algorithm, but other environment parameters to obtain a desirable controller. We posit that scaling RL to diverse robotic tasks will only be achieved if the community focuses on automating environment shaping procedures.
An ultimate dream of every roboticist is to create an Automatic Behavior Generator; a magical box that can produce performant robot controllers by just specifying the robot we're trying to use, the environment it's going to be deployed in, and the task we want it to perform.
What do you think about this dream? Are we being too optimistic, overly ambitious? Do you think this day will ever come?
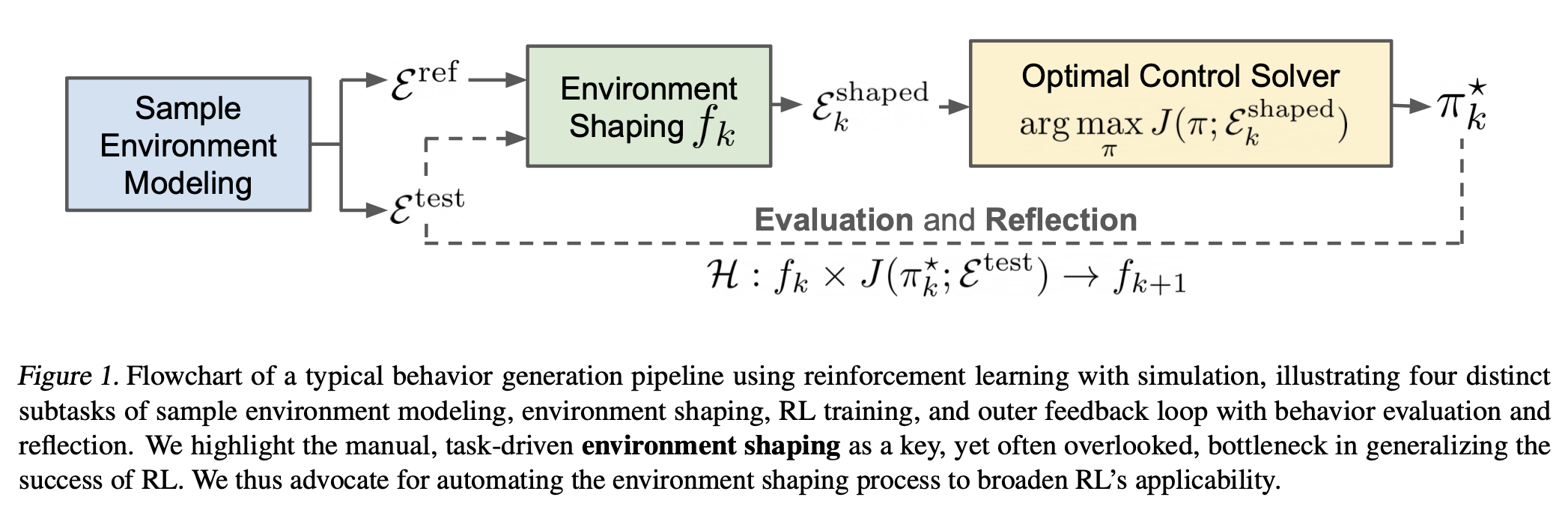
Definition 2.3 (Environment Shaping). Environment Shaping is a process of modifying a reference environment with design choices specifically optimized for learning performance. The purpose is to smooth the optimization landscape for RL so it can find better solutions that better performs in its original reference environment.
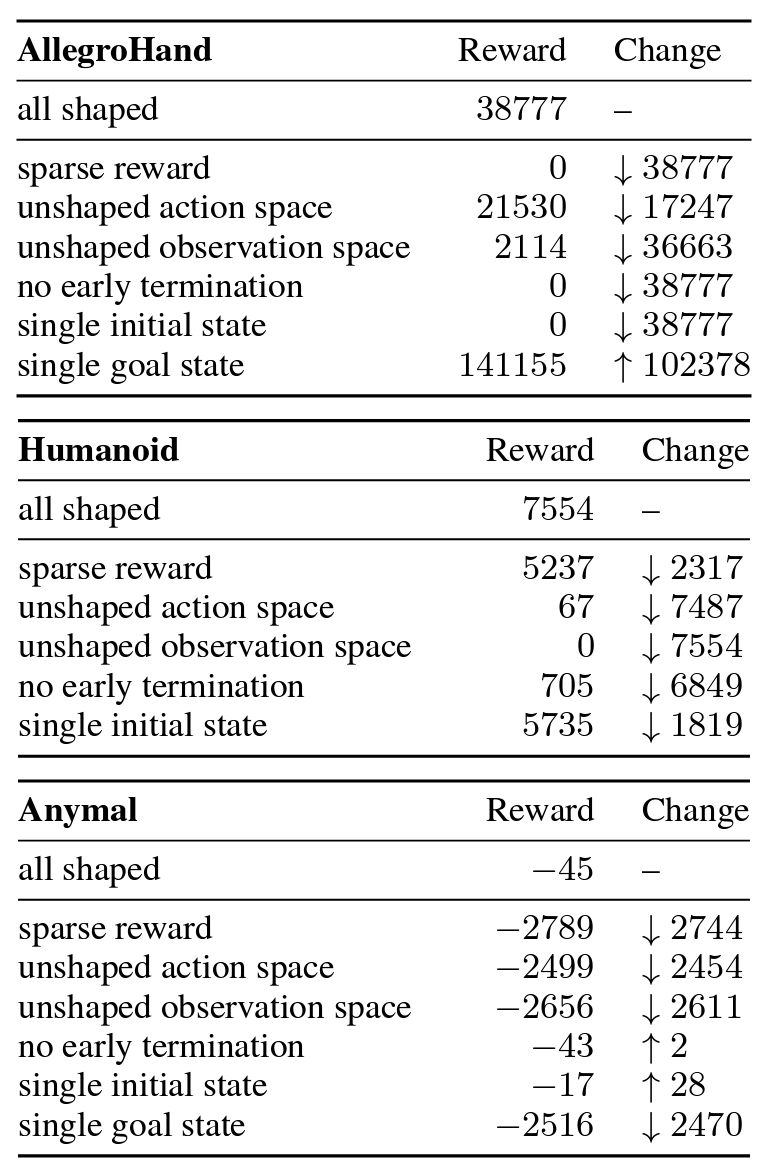
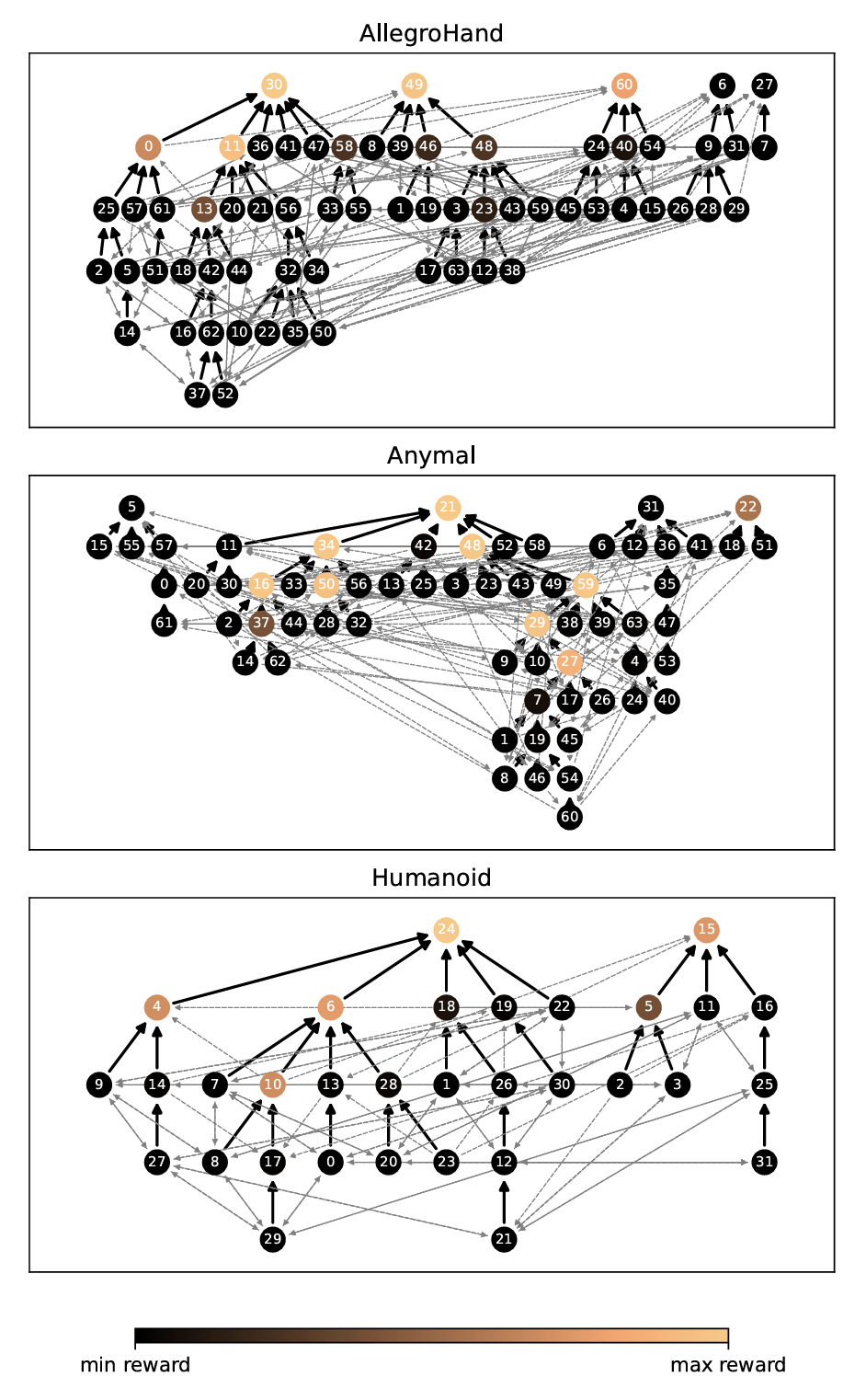
Common benchmark environments are highly sensitive to shaping, often with numerous local minima in the shaping design. Each node on the right represents a shaped training environment. Edges connect environments that are separated by modifying one type of shaping (action space, state space, reward function, initial state, goal, or terminal condition). Bold arrows represent optimal choices for hill climbing. Each environment is shown to have multiple local optima corresponding to the top row of nodes.
The problem of reward shaping is well known to the community; unfortunately, environment shaping doesn't just end with reward. Robotics engineers carefully shape nearly every component of the environment to make RL work in practice, including its action space, observation space, terminal condition, reset strategy, etc.
In this section, let's go through some examples of environment shaping that are commonly found in robotics RL environments.
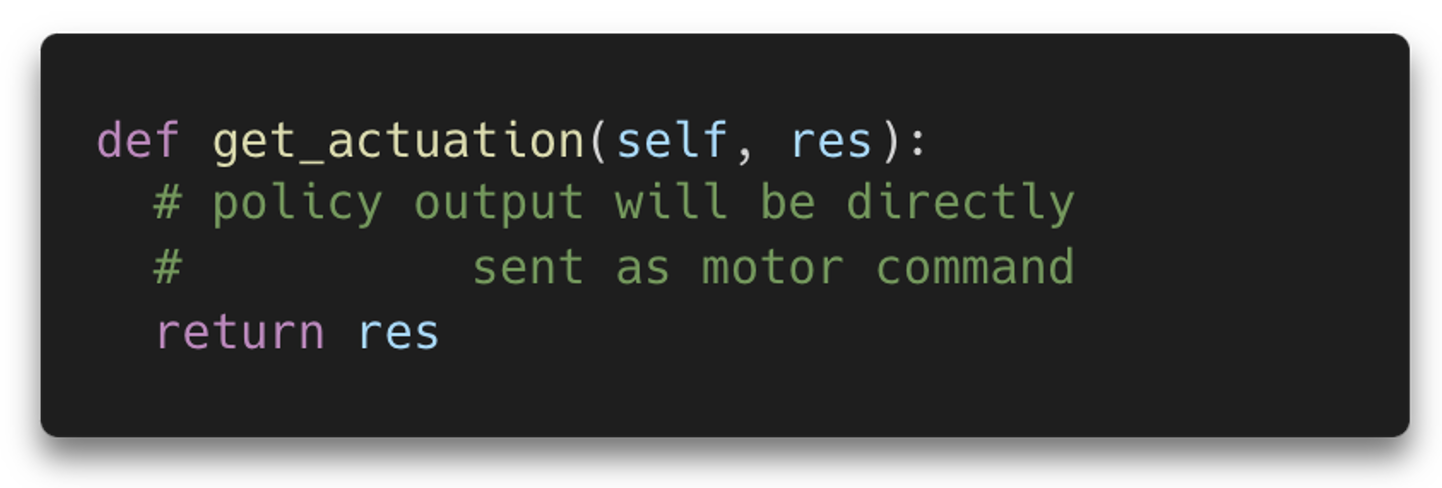
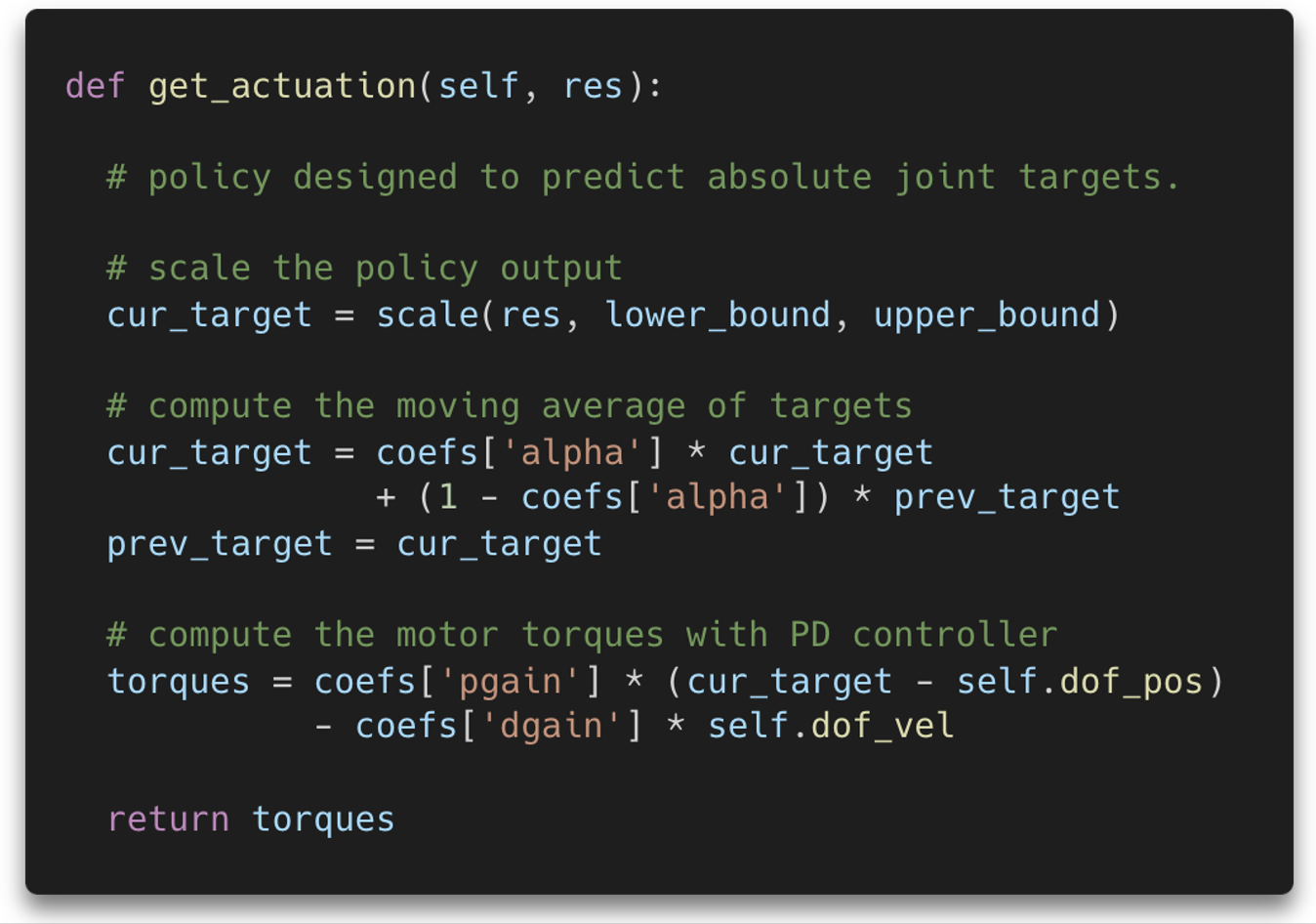
Action Space Shaping | In the context of robotics, action space shaping is basically a process of choosing how to convert the action predicted by the policy to a command that the motor can accept.
Reset Strategy Shaping | A reasonable unshaped reset strategy might be to always start from a nominal state defined in reference environment; manually designed sample environment with every actors (robots and assets) staying in its nominal pose. We often assume such nominal pose to be a mean of its underlying distribution, commonly assumed as Gaussian or Uniform distribution. This is indeed the most simple yet common technique of designing initial state distribution for many robotics tasks – we just randomly perturb robot joints and assets around its nominal (reference) pose!
When the task gets more complex, however, this simple approach starts to break quickly. Imagine randomly perturbing a single nominal state of a dishwasher, or randomly perturbing the nominal pose of a quadruped standing on a rough terrain; dishes and ladles, feets and terrain will be in penetration most of the time. Doing rejection sampling can be a stopgap solution, but it might end up rejecting most of the samples, making the approach nearly unusable. In practice, robotics engineers thus take a clever, but heavily heuristic, task-dependent approach to shape initial states.
For more detailed examples of environment shaping, read the full paper.
 Full Paper
Full Paper
 Twitter
Twitter